안녕하세요 푸키입니다. 오늘은 머신러닝의 배치학습과 온라인 학습에 대해서 이야기하겠습니다.
글의 흐름
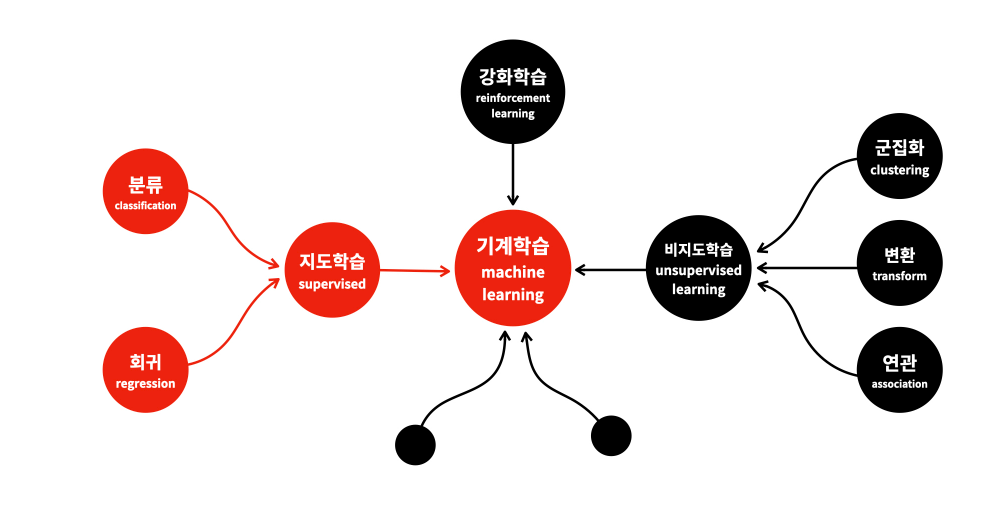
< 머신러닝 >
1. 머신러닝 분류 (1) 회귀와 분류
2. 머신러닝 분류 (2) 배치학습과 온라인 학습 << 현위치
3. 머신러닝 분류 (3) 사례 기반과 모델 기반
4. 데이터 인코딩/ 피처스케일링/ 교차검증
5. 주요 머신러닝 모델 소개
< 딥러닝 >
1. 그래프 모델 개념 및 신경망 기본 구조 소개
2. 전방향 연산, 가중치 초기화, 배치 기반 연산학습. Regularization 기본 개념
3. 신경망에서 학습의 의미, 역전파 기본 개념 및 chain Rule 을 이용한 학습
4. RBM 구축 과정, 수학이론, 구현 연습
5. CNN 개념
6. 다양한 딥러닝 모델 소개
머신러닝 분류 (2) 배치학습과 온라인 학습
머신러닝 시스템을 분류하는 데 사용하는 다른 기준은 입력 데이터의 스트림으로부터 점진적으로 학습할 수 있는지 여부입니다. 배치 학습과 온라인 학습이 있습니다.

배치 학습이란?
배치학습에서는 시스템이 점진적으로 학습할 수 없습니다. 데이터를 모두 사용해 훈련하기 때문에 오프라인에서 수행되기 때문에 오프라인 학습이라고 합니다. 학습 시스템이 새로운 데이터에 대해 학습하려면 전체 데이터를 사용해서 다시 처음부터 시작해야 합니다. 다행히 전체 과정이 쉽게 자동화 될 수 있어 변화에 적응할 수 있습니다. 따라서 배치 학습은 잘 작동하지만 전체 데이터셋을 사용해 훈련하는 데 몇 시간이 소요될 수 있습니다. 따라서 빠르게 적응해야 한다면 다른 방법이 필요합니다
온라인 학습이란?
온라인 학습에서는 데이터를 순차적으로 한 개씩 또는 미니배치라 부르는 작은 묶음 단위로 주입하여 시스템을 훈련시킵니다. 새로운 데이터 샘플을 학습하면 학습이 끝난 데이터는 더 이상 필요하지 않으므로 버리면 됩니다. 따라서 매우 큰 데이터셋을 학습하는 시스템에도 온라인 학습 알고리즘을 사용할 수 있습니다. 여기서 중요한 건 학습률입니다. 변화하는 데이터에 얼마나 빠르게 적응할 것인지를 학습률이라고 하는데 학습률을 높게 하면 시스템이 데이터에 빠르게 적응하지만 예전 데이터를 금방 잊어버리고 학습률이 낮으면 속도가 느립니다. 온라인 학습에서 가장 큰 문제는 시스템에 나쁜 데이터가 주입될 때 시스템 성능이 점진적으로 감소합니다.
푸키였습니다 좋은 하루 되세요!
마음에 드셨다면 공감 부탁드립니다. 오류가 있다면 댓글로 알려주세요. 끊임없이 수정하고 있습니다.
'전기전자 전공 분야 정리 > machine learning' 카테고리의 다른 글
| [machine learning] 머신러닝이란? 머신러닝 분류(1) 머신러닝의 회귀와 분류 (1) | 2024.01.27 |
|---|---|
| [machine learning ] 캐글 사용법 (2) | 2024.01.26 |
| [machine learning] CNN이란? (0) | 2024.01.20 |